An in-depth look into the single-threaded JavaScript event loop.
Writing effective JavaScript code requires a good understanding of the Event Loop and its components. Here we take a deep dive exploring this area.
If you have ever written a GUI (graphical user interface) desktop application you will know what it means to write an event-driven program. Event-driven means that event handlers (functions) are getting triggered by events that occur in the window or the application. Examples of these events include: mouse move, mouse click, typing on a keyboard, window resize, etc.
Some JavaScript developers don't realize this, but writing web apps involves the exact same event-driven paradigm. The code responds to a variety of events, such as, load, click, and submit. Internally, the browser manages an event loop which fetches events from an event queue. In this section we will take a deep dive into these concepts because it is important that you understand the event model to be able to write effective code. If not, you may end up with non-responsive pages that will potentially drive your users crazy.
JavaScript's eventing system is best explained with a diagram which you see below:
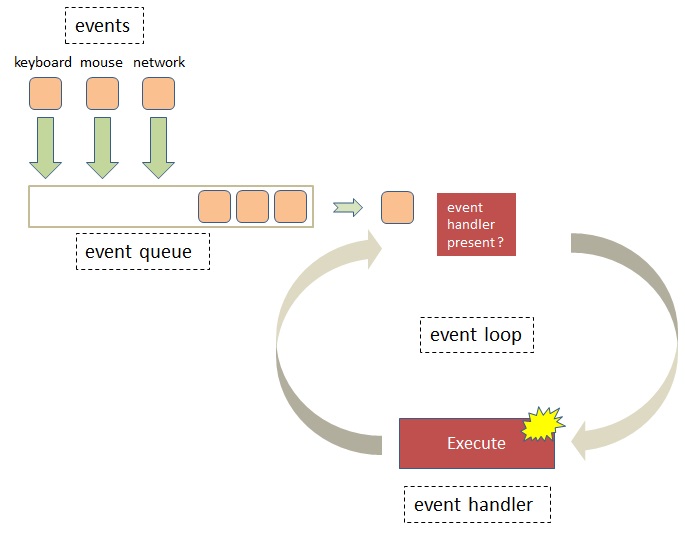
The general flow in this diagram is from the top-left to the bottom-right. There are 4 main parts to the system: 1) events, 2) the event queue, 3) the event loop, and 4) event handlers (also called listeners).
This runs internally in the browser and as a JavaScript developer your direct interaction with these parts is fairly limited. All you are doing is writing the event handler’s at the very bottom and hooking these up with certain events; the rest is managed by the browser.
Let’s start by reviewing the events. Events are actions that the browser will respond to. Three main types of events are:
All these events get placed into a queue which is called the Event Queue. This queue is FIFO (First In, First Out), meaning, the event that arrived first will also be processed first. FIFO queues work just like lines in a bank; you file at the end of the line and wait for the other patrons in front of you to be serviced until it is your turn.
Next comes the Event Loop; when an event arrives at the front of the queue, the event loop takes the event off the queue and checks if an Event Handler is available to process the event. If there is none it will simply ignore the event and look for the next Event in the queue (as an example, many mouse move events are generated and placed on the queue, but frequently there is no handler for these). However, if there is a handler (i.e. function) then it invokes it and the loop waits until it is done processing.
During the time that the handler executes the event loop can’t do anything but wait. Only when the handler is finished will it give control back the event loop which, in turn, will cycle back to the queue and look for the next event.
The loop in the browser is single-threaded. This means that at any point in time only a single item can execute; there will never be a situation where two or more event handlers execute at the same time. This single-threaded loop is also referred to as the UI thread, i.e. User Interface thread.
The advantage of having a single-threaded event loop is that they are relatively easy to program whereas multi-threaded programs are much more difficult (more difficult to debug rather). However, a disadvantage of single threaded UIs is that it is easy to block the browser event loop resulting in the appearance of frozen pages that do not respond to user actions anymore. The user may click on page elements or type on the keyboard, but nothing happens. This creates a terrible user experience and should be avoided at all cost.
Here is a simple example of that scenario. Say you have some code that needs to execute immediately after the page loads. You include the following code:
<body onload="loaded();">
And here is the JavaScript function which takes 5 seconds to execute:
<script type="text/javascript">
function loaded() {
// takes 5 seconds to process
}
</script>
Let's see how the event loop processes the above code. When the page is done loading a load event is added to the queue. Once that event reaches the front of the queue, the event loop will pull it off the queue and find that an event handler named loaded is registered to handle the event. The event loop gives control to loaded which then starts executing. The problem is that it takes a long time (5 seconds) to complete.
The page is fully rendered and as far as the user is concerned ready to go. They starts clicking on the page to be able to enter some data. However, nothing happens. All the actions that the user just took are, in fact, placed as events in the queue, but the event loop cannot process them because it is still waiting for the loaded function to complete.
This clearly demonstrates that writing long running functions is not the way to go. In JavaScript you should always write handlers that are succinct and very efficient at what they do. Always keep this in mind when composing your scripts.
The reality is that some functions just take time. For example, calling into remote servers may take a couple seconds before they respond. In situations like these you use a technique called asynchronous callbacks which is explained shortly.
First, we'll look at another example. Say you have the following markup on your page.
<a id="link" href="#" onclick="alert('Hello');return false;">say hello</a>
The onclick tag indicates to the browser that if the user clicks on the link that you wish to process the event handler. By the way, the return false; stops the browser from continuing with the standard action, which is to follow the href link. This particular handler is inline, but it is better to separate these out, like so:
<a id="link" href="#" onclick="clickHandler();">say hello</a>
<script type="text/javascript">
function clickHandler () {
alert('hello');
return false;
}
</scipt>
This is preferred over embedding JavaScript code in the HTML markup. According to the principle of Unobtrusive JavaScript and layering it would even be better to remove the onclick tag from the HTML altogether. You can then hook up the event handler in your code, like so:
<a id="link" href="#">say hello</a>
<script type="text/javascript">
var element = document.getElementById("link");
element.addEventListener("click", clickHandler);
function clickHandler (e) {
alert('hello'); // => hello
alert(e.screenX + ", " + e.screenY); // => 445, 542
alert(e.shiftKey + ", " + e.altKey); // => false, false
alert(this.id); // => link
return false;
}
</script>
Test it by clicking here: say hello
Three quick points we like to make: 1) the addEventListener is not available in older versions of IE (version 8 and below); you can use attachEvent which is very similar, 2) this kind of code is better handled with jQuery, and 3) registering event handlers with an event is an implementation of the Observer pattern, which is discussed in the Classic Patterns section.
Going back to the code, separating the JavaScript out from HTML is good practice because of the Unobtrusive JavaScript principle. But there are additional advantages. The onclick tag allows a single function assignment, whereas addEventListener, as its name implies, allows multiple click handlers for the same HTML element. Another advantage is that the handler will receive an event argument which has all the details of the event, such as the x and y location of the mouse cursor and whether the shiftKey and/or altKey were pressed. Finally, the event handler's context (the this value) is set to the HTML element where the event originated which is very helpful.
When the user clicks on the link, the click event gets added to the event queue. Once it reaches the front of the queue, the event loop pulls it off the queue and determines that one or more event handlers are available for the event and it hands control over to these handlers which then start executing.
As mentioned, handlers that register themselves with addEventListener receive an event specific event argument and the this value is set to the HTML element where the event occurred. If you're familiar with the built-in apply or call methods you will understand that this is how the event loop invokes the handlers (note: the Apply Invocation pattern is discussed in the Modern Patterns section).
Callbacks
Event handlers are also referred to as callbacks. Callbacks are function references that are passed around to other functions which will call these function
references back (i.e. execute the function) at the appropriate time.
Callbacks are an important concept in JavaScript and their use is not limited to event handlers. You can write custom functions that accept callbacks which they can invoke. Here is an example:
function mathematics(x, y, callback) {
return callback(x,y);
}
function add(x,y) { alert(x + y); }
function multiply(x,y) { alert(x * y); }
mathematics(3, 5, add); // => 8
mathematics(3, 5, multiply); // => 15
Run
Here we are passing two callbacks, add and multiply, into mathematics. There they get invoked with the () operator which also passes in the x and y values. Essentially these are plug and play functions (which is the Strategy Design Pattern). A built-in JavaScript example is the Array.sort method which accepts a callback that does the comparison of two array elements. Here is some example code that demonstrates it in action:
var arr = [23, 4, 99, 15];
arr.sort();
alert(arr); // => [15, 23, 4, 99] – not good
function compare(x,y) { // callback
return x - y;
}
arr.sort(compare);
alert(arr); // => [4, 15, 23, 99]
// or inline
arr.sort(function (x,y) {
return x - y;
});
alert(arr); // => [4, 15, 23, 99]
Run
The first sort is not what we need. It sorts the numbers as strings and they are not in numeric order.
The compare callback is called by the Array for each pair of numbers in the array that need comparison. If the returned value is positive the numbers will be reversed; if zero the numbers are equal, and if positive the order is correct. Simply subtracting y from x will create the above comparisons. The callback is passed into sort and the result is a perfectly sorted array.
The last statement shows a common shorthand; the compare function is passed inline, directly as an argument into the sort method.
Asynchronous callbacks
Earlier we mentioned asynchronous callbacks. This is a technique that prevents long running functions from blocking the UI.
They are an important tool in the toolbox of every JavaScript developer.
Asynchronous callbacks are callback functions that are invoked asynchronously, meaning at a later time.
As an example, JavaScript has a built-in function called setTimeout that allows callbacks to be called asynchronously after a given number of seconds:
function say() {
alert("Hello");
}
setTimeout(say, 2000); //=> after 2 seconds: Hello
console.log("I am here"); //=> immediately: I am here
Run (takes 2 seconds before it responds)
As an aside, we use console.log in the last statement rather than alert because it is non-blocking. Most browsers support console.log which writes to the JavaScript console. Open your console, run the code and see for yourself.
When running the above snippet, we will see "I am here" (on the console) before "Hello". The setTimeout method schedules the callback for execution with a delay of 2 seconds and then returns immediately allowing the next line to execute. After a 2 second delay the say callback method gets called. This demonstrates that the invocation of say does not does not block the UI thread and is therefore an asynchronous callback.
How does the JavaScript engine accomplish this? It turns out that setTimeout simply places the execution event on the event queue. It informs the queue that this event has to wait for 2 seconds before it can be pulled off the queue by the event loop. After two seconds the execution event sits at the front of the queue, the event loop picks it up and starts executing the requested say function.
Zero Timeout pattern
Long running JavaScript scripts can cause the browser to freeze up or result in the dreaded "Script is taking too long" message.
In situations like this setTimeout with zero delay may be of help. Calling setTimeout with no delay is called the Zero Timeout pattern. It allows you to break up long running JavaScript functions in smaller pieces. By breaking it up, you are giving the browser and the event loop some breathing room, allowing it to catch up with whatever it needs to do.
We are discussing the Zero Timeout pattern here because it relates to the event loop. However, strictly speaking if falls under the Modern Patterns category.
The Zero Timeout Pattern is frequently used in syntax highlighters which highlight certain selected text on a web page. They need to scan the entire page to find and modify the selected text which may take a few seconds. You've probably seen these text highlights (usually yellow) as some web pages highlights the words that the user searched for coming from a search engine.
Here is an example in which a div element continually changes size. The first snippet is the HTML which has a start, a stop, and a reset button, as well as the actually div that changes size.
<div id="myDiv" style="width:10px;height:50px;background:#f00;"></div> <button class="btn" onclick="start();">Start</button> <button class="btn" onclick="stop();">Stop</button> <button class="btn" onclick="reset();">Reset<button>
Next is the JavaScript code. Notice that in the function body of func we call setTimeout(func, 0) which calls itself without delay. Once the size of the div has reached 600 pixels it stops.
var timeout;
function start() {
var div = document.getElementById("myDiv");
var size = 10;
var func = function () {
timeout = setTimeout(func, 0);
div.style.width = size + "px";
if (size++ == 600) stop();
}
func(); // starts the process
}
function stop() {
clearInterval(timeout);
}
function reset() {
var div = document.getElementById("myDiv");
div.style.width = "10px";
}
Test it here:
Although we state 0 delay there will be a slightly longer delay because during these delays the browser is catching up with the pending size changes in the DOM. Also, the function clearInterval, as used in stop removes the pending event identified by the timeout id from the queue.
Next, we'll run it as a simple loop without setTimeout. We are making very small increments to slow the loop down a bit. Notice that the loop does not allow the browser to update the DOM, therefore, you'll most likely see the div jump from 10px to 600px following a small delay.
var size;
function start() {
var div = document.getElementById("myDiv1");
size = 10;
while (size < 600) {
div.style.width = Math.round(size) + "px";
size += 0.002;
}
stop();
}
function stop() {
size = 600;
}
function reset() {
var div = document.getElementById("myDiv1");
div.style.width = "10px";
}
Test it here:
We have discussed asynchronous callbacks that get placed on the event queue. In fact, all events placed on the event queue are asynchronous because there is a delay between when the event occurs and when the event gets handled by the event loop.
We mention this because there are also synchronous (not asynchronous) browser events. These are events that are so critical that they need to be executed immediately, even when JavaScript is in the middle of running some code.
An example of such an event is mouse move. Indeed mouse move events get entered into the event queue, but the actual mouse pointer (the arrow or hand) that hovers over the page updates immediately. If this were not the case, users would see jerky and erratic mouse pointers -- all the time.
Another example is DOM manipulation. Suppose your JavaScript program has a click handler that changes the background color of the element that was clicked. The browser will treat this as a synchronous event and processes it instantly. Another example is when JavaScript executes focus() on a screen element. This will place focus immediately to that element. We should mention that there are some slight differences between browsers as far as which DOM mutations are processed synchronously.
All this clearly demonstrates that internally the browser is multithreaded but the event-loop, which is what we as JavaScript developers interact with, runs as a single thread.
Ajax calls
Thinking about Ajax and the event loop, you may be wondering what happens between when an Ajax call is made and when a (delayed) response comes back;
how does the JavaScript engine know when to start executing the callback? You probably guessed it: our trusted event queue is involved.
Following an Ajax call, the browser detects when the network call comes back. The details of how this works do not matter because this is native code and each browser has its own implementation of the XMLHttpRequest object. The bottom line is it just knows when the network call has come back.
When this occurs an event gets added to the event queue. This event is an execute request for the callback including a reference to any return values. Any pending events on the queue will be processed first, but once the event reaches the front of the queue the event loop will fetch it and start executing the callback and provide it the result values from the server call.
